
Accelerating Flow with DevSecOps and the Software Factory
By Peter Vollmer, Distinguished Technologist, Micro Focus
![]() Note: This article is part of the Community Contributions series, which provides additional points of view and guidance based on the experiences and opinions of the extended SAFe community of experts.
Note: This article is part of the Community Contributions series, which provides additional points of view and guidance based on the experiences and opinions of the extended SAFe community of experts.
Introduction
Large Enterprises have a huge opportunity to accelerate their business by applying SAFe® and DevSecOps practices. SAFe provides guidance to organize around value, improve quality, reduce lead time, increase employee satisfaction, and apply Lean-Agile principles and values.
This article provides further guidance to succeed with your DevOps implementation. It describes how you can practically apply shift-left practices with the ‘DevOps Evolution Model’ and how you can eliminate bottlenecks in your DevOps pipeline by applying CI/CD pipeline modeling. To reduce cognitive overload and to improve productivity, it presents a software factory and the value of standard engineering services. Finally, as security becomes even more critical to software development, we show how to apply discussed approaches for a successful DevSecOps implementation.
Two Helpful Models to Shift Left and Eliminate Bottlenecks
“Mental models are deeply ingrained assumptions, generalizations, or even pictures or images that influence how we understand the world and how we take action.” —Peter Senge, The Fifth Discipline
A shared mental model helps teams and organizations generate a common understanding of a problem. It builds the starting point to work together, discovering various solutions, and select the most promising ones for implementation. The next section of this article discusses two such models—the DevOps Evolution Model and CI/CD pipeline modeling.
The DevOps Evolution Model
The DevOps Evolution Model shows organizations how to decrease lead time and reduce feedback cycle length. Large enterprises already have successful, established products in the market. Unfortunately, their release cycles commonly range from 6 to 18 months. When moving to SAFe, enterprises start reducing their release cycles by moving through phases described in Figure 1. The main question for the DevOps transformation at this point revolves around how to reduce the finalization phase over time.
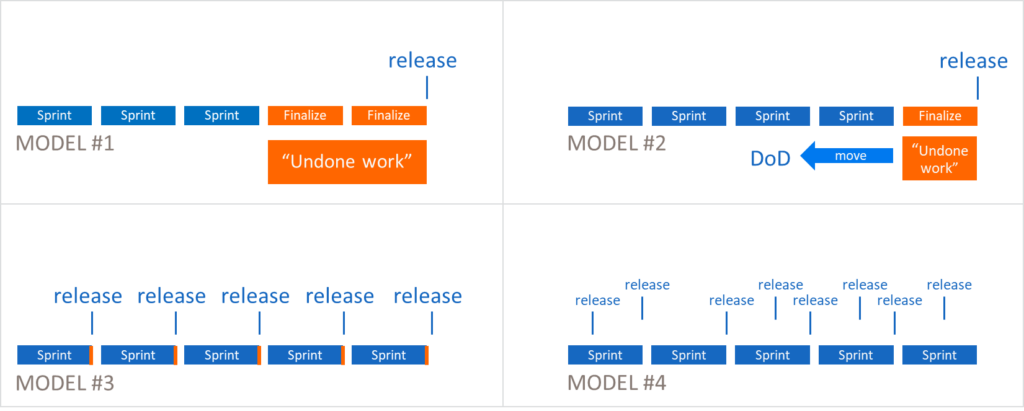
Model #1: Even though teams develop in iterations, additional iterations are required to release the solution. This ‘undone work’ is what remains after normal development activities. It was not part of any Definition of Done (DoD).
Model #2: Teams start shift-left efforts by moving undone work into the DoD.
Model #3: Undone work is minimized to an extent that it fits at the end of each iteration.
Model #4: Undone work is eliminated completely, a continuous delivery model is achieved, and a high-quality release per Feature, Story, or any other code change is possible.
Discover undone work
Undone work is additional work required to release the solution after the team is ‘done’ with a Feature or Story. Ideally, the DoD includes all these items, but in practice this is rare.
The DoD can exist at multiple levels: Story, Feature, Iteration, System Demo, Solution Demo and Release.
In Model #3, the release DoD is the same as the iteration DoD. In Model #4, the release DoD is already included in the Feature or Story DoD or as part of the CI/CD automation. Not all products can achieve Model #4 nor is it always economically desirable. SAFe Principle #1—Take an Economic View—helps us find the right trade-off.
Move undone work into the DoD—aka shift left
Moving undone work into the DoD is called a ‘shift-left’ activity. Doing these activities earlier provides feedback that enables faster learning and quicker response. This has several benefits:
- There is a high correlation between shorter feedback cycles and the ability to learn from the feedback. For example, it would be impossible to learn to play the piano if you were to hit a key today and have the piano play the sound two weeks later. The same is true for software development.
- Reacting earlier to feedback usually requires less effort for corrective actions, such as fixing a bug or implementing an even better solution. This leads to higher quality and productivity.
- Shorter cycle times reduce WIP and therefore increase flow.
- Reducing or eliminating undone work phases increases flexibility to release more often and allows faster response to requirement changes.
Prominent examples of undone work are:
- Security checks and audits
- Manual testing
- Test environment setup
- Deployment
- Documentation
- Globalization, internationalization, and related tests
- Open-source legal assessments
- Compliance checks
Architect for more frequent releases
Moving undone work left supports SAFe Principle #6—Visualize and limit WIP, reduce batch sizes, and manage queue lengths—and improves flow. However, many system architectures make shifting left too costly. Applying Principle #6 requires changing the architecture to support more automation in an economically reasonable manner. However, getting faster only makes sense if the degree of quality is good enough. Many organizations that misunderstood this concept could not harvest the benefits of DevOps [1].
We can learn this concept from professional musicians who typically pick up new, complicated sections slowly at first, mastering timing, tone, etc., and then increasing the playing speed.
Model your CI/CD pipeline
Models simplify the real world, describing known things in a way that generate new useful insights. This is the intention of the CI/CD pipeline modeling, similar to SAFe Value Stream mapping but focuses specifically on the CI/CD pipeline. If properly applied, the model helps optimize lead time by uncovering bottlenecks and delays so teams know where to best invest in improvements.
To create the model, you bring all relevant people together to draw your entire pipeline process (build, integration, deployment, etc.) as nodes and edges. Nodes represent the components and edges describe the relationships between the components. The deployed and operational solution is represented by the final node on the right (Figure 2). Lead and process times plus percentage complete and accurate (%C&P) are assigned to each node (see the Continuous Delivery Pipeline article for more detail) and findings are tracked in the improvement backlog and prioritized with WSJF along with the other backlog item.
While one would think the teams already know their end-to-end pipeline and would find the whole effort useless, this has surprisingly never been the case.
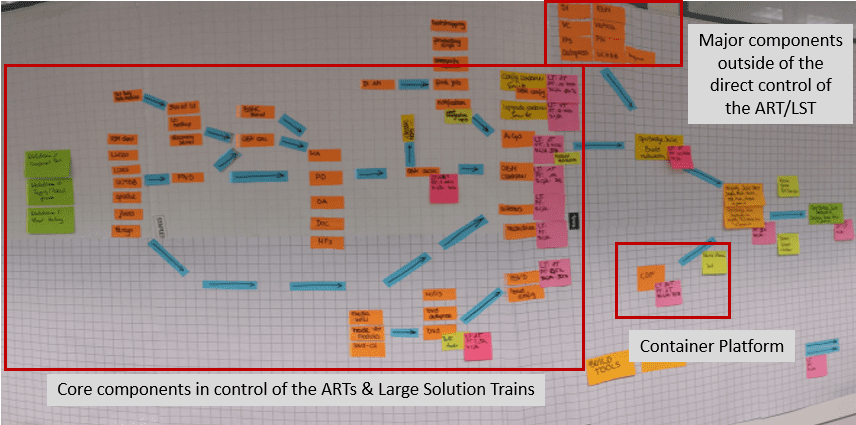
This modeling uncovers many improvement items. In large solutions, no single person understands the end-to-end CI/CD process. But by bringing the right people together, they understand the big picture and see the suboptimal results of local optimization. This modeling reveals many questions:
- Why do they have a dependency here but aren’t doing more testing there?
- Why is this component so large?
- Why does this step take so long and why does another step have such a low %C&A, leading to double or triple effort in a later step?
- Why are new versions of components consumed very rarely, finally causing trouble during integration?
Here’s another interesting observation: while people often claim that they build and deploy several times a day, in many cases they are building and deploying the same code or components over and over again. The key question for CI/CD improvements is not the number of pipeline runs but how long it takes from writing the code until it arrives in staging or production. This is the most important question to ask for each contributing component.
Quality also plays a critical role in lead time. Components that have backward-compatibility issues, break interface contracts, or have critical defects delay changes to other components that utilize it.
One major success factor in this process is the quality of each contributing component. If the quality is low, e.g., backward-compatibility issues or too many critical defects, consumers tend to delay the consumption of this component (high transaction costs lead to larger batches). This eventually leads to longer lead times for code changes in the integrated solution on staging or production—in other words, longer instead of shorter feedback cycles.
A severe implication of these delayed integrations are potential showstopper defects. If they are discovered late and fixes and required integrations take more time, this can break release commitments. The solution to apply shortcuts and workarounds to hold the schedule, decrease quality, and increase technical debt.
As a result, the trust between the business and development erodes, market windows are missed, or delivered solutions fail. Subsequent functionality is delayed by earlier technical debt and worsens the whole situation—thus, the downward spiral continues.
Reduce Cognitive Load and Increase Productivity with a Software Factory
“Since we are using SAFe and the Software Factory, we can create new Development Value Streams or adjust existing ones with minimum overhead and maximum productivity.” —SVP R&D, Micro Focus
Benefits of a software factory
Building enterprise software is a complex endeavor. It requires many skills and experience to create usable, robust, scalable, and secure solutions that can quickly be enhanced and aligned to new business needs. Organizations that can master this challenge will have a huge advantage in the digital age [2].
Software factories reduce the team’s cognitive load. Organizations that have adopted SAFe can create and change development Value Streams with minimal effort. People already share the same language, mindset, and can quickly adjust strategy in response to opportunities or threats. A software factory extends and enhances that shared alignment through standardized tooling and engineering services that support and enhance them. Standardizing on a common tooling for Application Lifecycle Management (ALM) and Build Factory (CI, SCM, artifact repositories, testing services, release management, etc.) simplifies and enables easier collaboration across Teams, ARTs, or Solution Trains—and makes it easier to move people between them.
Unfortunately, the complex tool chain requires broad T-shaped teams and team members. This often results in significant cognitive overload within many teams. Consequently, these teams will frequently deliver suboptimal product quality with higher lead times. A software factory standardizes tools and builds engineering services around those tools. This reduces cognitive load and facilitates continuous improvement and high-quality implementations. As the software factory grows, it will include non-functional tool chain requirements such as reliability, security, monitoring, compliance, maintenance, disaster recovery, and data protection.
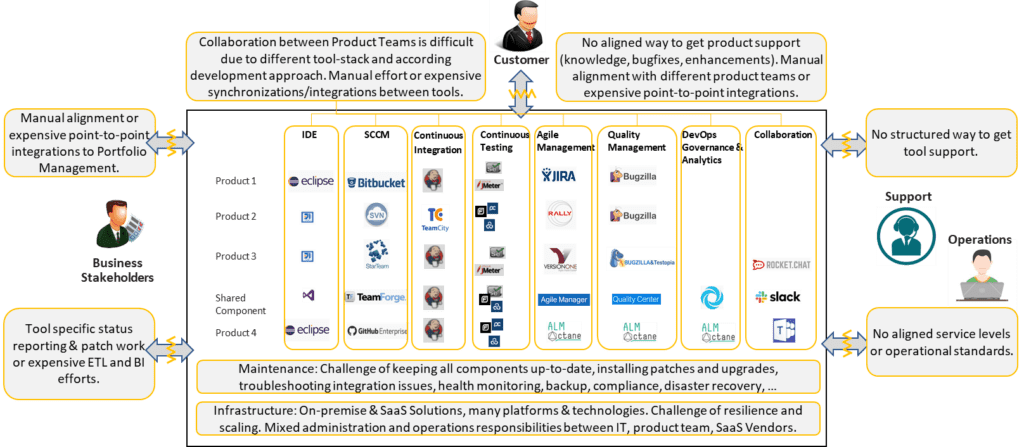
Software factories also reduce costs. Over time, large enterprises acquire a large, diverse set of tools that are either expensive to integrate, poorly integrated, or not integrated at all. Companies lose track of their inventories and pay unnecessarily high license fees. A software factory consolidates tools and their integrations, focusing on a high-quality implementation with supported and maintained integrations. As part of engineering services, subject matter experts maintain and continuously improve the systems and infrastructure.
A software factory follows the same Lean-Agile principles used in product development. Incremental approaches based on validated experiments and user feedback are essential. Usage should be driven by the attractiveness of the solution and voluntary adoption. Guardrails set by the leadership team balance global vs local optimization. The solution provides customization and adjusts to the specific needs of individual teams while ensuring acceptable levels of quality and predictability. Follow the motto: As much freedom as possible and as much standardization as necessary.
Scope and high-level architecture of a software factory
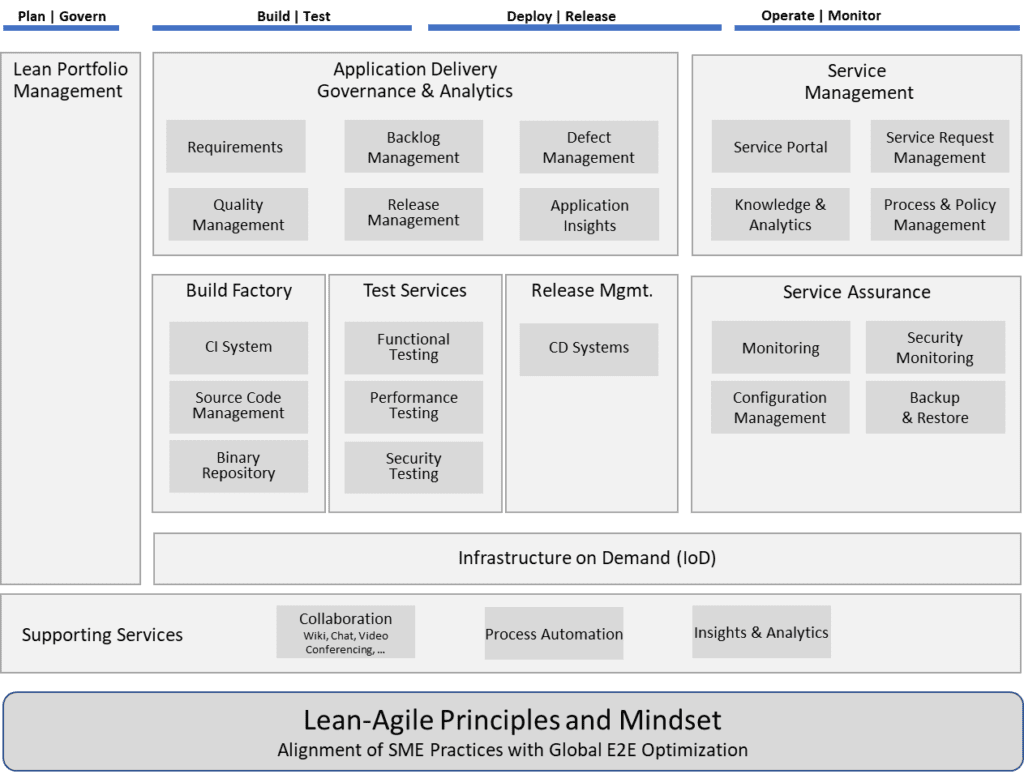
Building a software factory is an iterative and incremental effort. Tools standardization and engineering services are implemented based on the available resources and the speed of adoption by the product teams. The availability of individual tools or services can already be a great productivity improvement, however, the whole is more than the sum of the individual pieces. There are various synergy effects as services complement each other.
As mentioned above, a common set of ALM, SCM, and artifact repository tremendously enables collaboration. And standardizing the CI/CD pipeline and making it available as a service boosts productivity. Teams request a preconfigured pipeline with all plug-ins and integrations ready for use. Product-specific configurations are stored as configuration as code (CaC). Teams instantiate these pipelines as many times as required. All components are regularly maintained with the required upgrades and security patches, and knowledgeable experts are available to assist the teams.
In addition to tools and pipelines, the software factory must also offer:
- A service catalog that supports requests through self-service, or if that’s not possible, via tickets.
- Service Assurance for monitoring, configuration management, and data protection. Infrastructure on demand (IoD) is used to dynamically allocate compute and storage capacity to be able to scale-out and optimize resource utilization.
- Supporting services that provide integrated collaboration tools, process automation, and usage/cost tracking via analytics and insights.
- A Lean Portfolio Management tool that provides portfolio-level insights and enables coordination and orchestration of the development Value Streams.
The Lean-Agile Principles and Mindset are the foundation of the software factory, driving the evolution of the factory as well as guiding its own DevOps culture.
Implement DevSecOps by Applying the Models and Factory
Security is an extremely important topic as vulnerabilities can lead to existential business threats. Hackers are trying to harm businesses in many ways, such as by stealing intellectual property and customer data or trying to take over systems to obtain a ransom.
In this section, we will investigate how we can transform our current security practices to a DevSecOps mindset by applying the DevOps Evolution Model, pipeline modeling, and software factory services.
Security practices are not isolated activities but are usually embedded in a so-called security life cycle to address all security aspects. This life cycle covers questions such as:
- What security practices should we use as a business?
- What are the right security practices for a given product or solution?
- How do we enable teams to build appropriate security into the products?
- What roles and responsibilities do we need?
- How do we govern security to ensure we have the right degree of security in each product?
- How do we continuously evaluate and improve our security practices?
Define required security practices and degree of practices
The community has many proven practices to develop secure products, such as:
|
|
|
Within each practice there are certain degrees of implementation or maturity levels, depending on an organization’s business context. For example, a restaurant and a hospital have completely different considerations when cleaning floors that drive frequency, and supplies that trade off costs vs cleanliness. The same is true for product development. For each solution, there should be an informed decision about the appropriate security measures and applied maturity that inform a trade off of the costs (time, effort, team maturity) and desired security in the product. There is no value in a maximum secure product that never gets released and nobody can afford. Nor is there value in a poorly secured product that has significant usage risks.
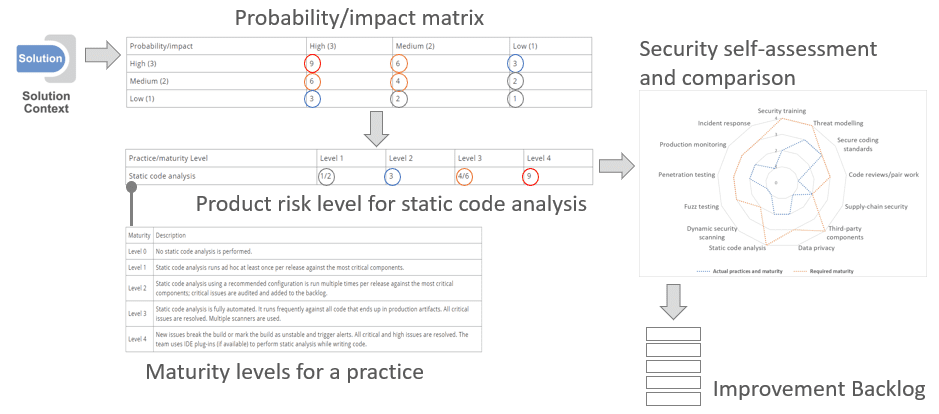
Specific maturity levels are specified for each security practice. The table below shows example maturity levels for static code analysis.
| Maturity | Description |
| Level 0 | No static code analysis is performed. |
| Level 1 | Static code analysis runs ad hoc at least once per release against the most critical components. |
| Level 2 | Static code analysis using a recommended configuration is run multiple times per release against the most critical components; critical issues are audited and added to the backlog. |
| Level 3 | Static code analysis is fully automated. It runs frequently against all code that ends up in production artifacts. All critical issues are resolved. Multiple scanners are used. |
| Level 4 | New issues break the build or mark the build as unstable and trigger alerts. All critical and high issues are resolved. The team uses IDE plug-ins (if available) to perform static analysis while writing code. |
Table 1: Example of maturity levels for static code analysis
A product risk level is the risk of potential security breaches. Risk is defined as probability that an event happens, multiplied by the impact of the event. Probability attributes, for example, represent how attractive and easy it is to breach the system. Impact attributes represent the damages a breach can cause to the organization and to customers. The risk matrix defines the level of risk and each product can be assessed by a simple risk matrix. High probability and high impact (3*3=9) lead to a 9. Medium probability and high impact (2*3=6) lead to a 6. This defines a certain risk level to each product.
| Probability/impact | High (3) | Medium (2) | Low (1) |
| High (3) | 9 | 6 | 3 |
| Medium (2) | 6 | 4 | 2 |
| Low (1) | 3 | 2 | 1 |
Table 2: Probability/impact matrix
By understanding the product risk level, the business can make decisions about the appropriate security practices and the required maturity level to be applied. This is done for each practice with an example for static code analysis as shown below.
| Practice/maturity Level | Level 1 | Level 2 | Level 3 | Level 4 |
| Static code analysis | 1/2 | 3 | 4/6 | 9 |
Table 3: Example of product risk level for static code analysis
Reading the table, for a product with low security requirements (risk level 1 or 2) maturity level 1 or level 2 is acceptable. For a product with high security requirements (risk level 9), we need to apply maturity level 4.
A security self-assessment compares the team’s scores with the required measures for a product or class of products (see Figure 5). Based on the result, the team can agree on the right improvement activities and potential required compromises to reach an optimum economic outcome.

Figure 6 below summarizes the steps to define a security classification process.
Applying shift left, bottleneck identification, and software factory services
Once the security practices and their maturity levels are defined, we apply our models, shift left, bottleneck identification, and software factory by analyzing each practice along with our current pipeline implementation. To explain the approach, we use static code analysis practices as an example, but this can be applied to any other practice as well.
During such an analysis we usually discover some specific scenarios:
- The practice applies too late in the pipeline and delays feedback, so we want to shift it left.
- The practice is a bottleneck and increases lead time, so we want to understand how the bottleneck can be reduced or eliminated.
- We do not apply or only partially apply the practice because it is too costly, either in terms of lead time or required resources.
- Due to the cognitive overload of the team, the practice is applied with low reliability and maturity. So, we investigate ways to relieve the teams and apply the practice via a service.
- We apply the practice but are not satisfied with the current maturity in how the practice is executed, so we want to increase the maturity without negatively affecting lead time or creating a bottleneck.
- The practice can be a combination of some of the above scenarios.
A good way to analyze the security practices is to compare your current pipeline position with the maximum shift-left position as described in the SAFe DevOps Health Radar.
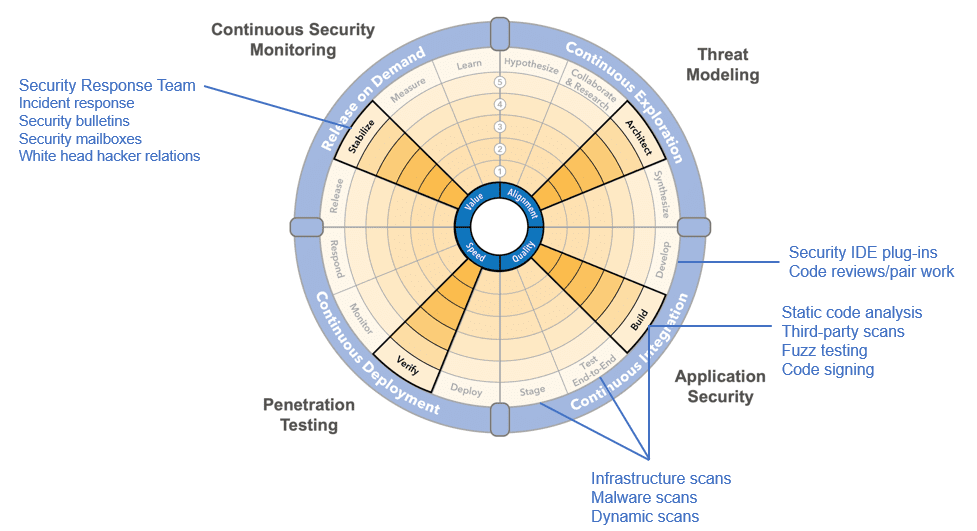
Continuous Exploration practices
Threat modeling analyzes a system to answer vulnerability questions such as, Where am I most vulnerable to attack? What are the most relevant threats? What do I need to do to safeguard against these threats? [3].
Threat modeling anticipates future potential threats and avoids or addresses them during feature design. If performed after the implementation, any changes in code and design would be too expensive and time-consuming, if possible at all. Therefore, shift left by conducting the threat modeling during design and manifest it in the feature’s Definition of Ready (DoR) and estimate. Results of the threat modeling activity are added to the feature’s description and are reflected in the acceptance criteria for validation.
Continuous Integration practices
Security IDE plug-ins give developers direct feedback while writing code. This promotes learning and is the least expensive way to both discover and fix vulnerabilities. Integrating the IDE plug-in to the static code analysis backend makes usage simpler by registering reviewed false positives to avoid repetition. A good plug-in also contains a knowledge base with further explanation about potential vulnerabilities and educates developers while they write code. Another advantage of IDE-level integration is the ability to directly add annotations (for the scanner) to the code, to mark false positives, and avoid new reappearances during refactoring.
Code reviews are the only way to assure certain code qualities, but they come with delayed feedback. Code reviews happen after analyzers uncover their issues, allowing the human code reviewers to focus on issues they cannot find. And, patterns from multiple code reviews can provide opportunities to automate rules inside the code analyzer.
Pair work provides real-time feedback directly during design or coding. It also raises and broadens the skillset for the entire team as teammates learn from each other, especially when pairs change over time or severity experts temporarily join a team.
Static code analysis uncovers potential vulnerabilities. Later, a developer review filters out and marks false positives, classifying vulnerabilities based on criticality and tracking them in the vulnerability backlog.
Third-party scans: What is true for your own source code also applies to third-party code. Any library or component should be evaluated by static code analysis, particularly those that are dynamically or intentionally updated during the build process.
Fuzz testing is used to bombard components at their interfaces with random data to test input parsers and their behavior for unexpected data including special characters, high volume, etc.
Code signing establishes authenticity and ensures that consumers can only execute unmanipulated code. Depending on the technology, code signing is performed for each build or the final code package. In some languages, code signing can change the behavior of the code and should be part of the build and testing process.
Infrastructure scans find weaknesses in computing infrastructure including malware and passwords in application servers, databases, or other services, and open ports, as well as outdated components such as old SSL, SMTP, and DNS versions.
Dynamic scans as part of end-to-end testing and in staging are used to discover vulnerabilities such as unnecessary open ports, configuration issues with components, outdated patch levels of operating system and other used components or packages, unwanted potential privilege elevation, default passwords for applications and services, authentication issues, stack overflow, denial of service attack and brute force vulnerabilities, SQL injection, cross-site scripting, weak HTTP cookies, etc.
Malware scans should be used for SaaS infrastructure and before packaging any component.
Continuous Deployment practices
Penetration testing (pen testing) attempts to breach IT systems by simulating any kind of hacker attack. This type of testing requires highly skilled professionals who can apply the same tools and techniques that real hackers would use. Any vulnerabilities found are tracked in the vulnerability backlog and fixed according to priority. As pen testing is mainly a creative and manual process, it is difficult or even impossible to fully automate and perform it in small increments. Because it is one of the few practices that we cannot easily shift-left, make these the common alternatives:
- Accept a delay for the release and perform pen testing before the release
- Have professional pen testers on the ART who try to frequently breach the staging environment
- Perform periodic pen testing on the production system and fix forward
Release on Demand practices
Continuous security monitoring monitors systems to find potential security breaches. This is usually done by a security information and event management (SIEM) system that incorporates advanced analytics such as event correlation, user behavior analytics, network flow insights, artificial intelligence, and incident forensics. With the collected data, security analysts can derive the proper actions and generate applicable security compliance and audit data.
The security response team gathers information about newly discovered vulnerabilities (security mailboxes, security bulletins, white hat hackers, etc.) and feeds this information back to the development and operations teams. Application providers issue security bulletins to inform customers about newly found vulnerabilities and any necessary measures to mitigate or fix them.
Build security practices into the software factory
Here is one example of how the software factory can provide significant productivity and quality improvements. This approach can apply to other practices as well.
Static code analysis is a great candidate for a software factory service. Because a single static code analyzer does not cover all potential vulnerabilities, several different analyzers should be used. Selecting and maintaining all these tools and related integrations would cause a cognitive overload of teams and if done in all teams, be an unnecessary duplication of work. So, product teams usually work with a suboptimal subset or just a single analyzer, unless there is an engineering service that provides a mature and reliable solution.
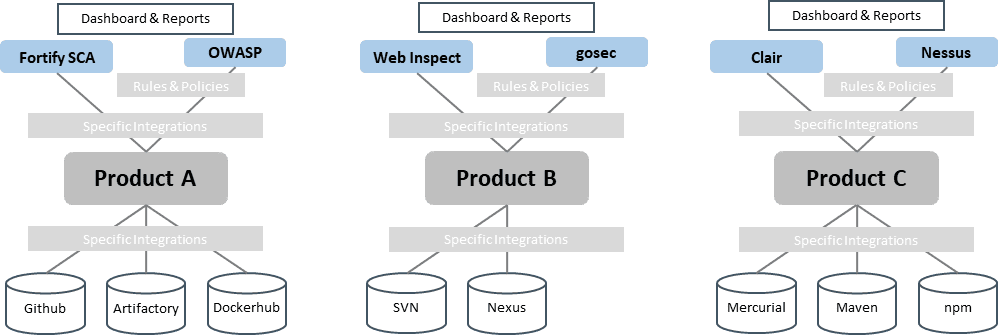
Specific subject matter experts can build a standardized engineering service that can be automatically plugged into the CI pipeline. Because the service is already preconfigured and consolidates results in a single vulnerability data and knowledge base, the engineering services team can centrally maintain updates and new content. Plus, the service can be extended with standard dashboards and reporting, a knowledge base, audit reports, IDE plug-ins, alerts and notifications, risk assessment support, and others. A key piece is the ALM tool integration to systematically track and prioritize found vulnerabilities and issues. The whole setup can be integrated into the larger factory services for standard monitoring, backup, disaster recovery, and resource optimization via infrastructure on demand (IoD), and a service portal.
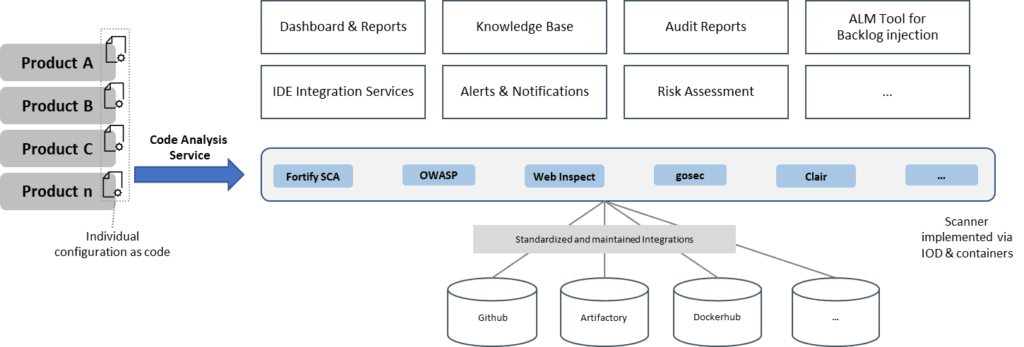
With this approach, all product development teams can benefit from the enhanced maturity and broader coverage of the scanning and the reliability and quality of the service. Consuming it as a service reduces the cognitive load, and instead of investing the time in tooling, integrations, and maintenance, the product team can invest in further security training and knowledge gathering.
History shows that product teams can set up associated tools but lack the time to care about backup, compliance requirements, or disaster recovery of used systems. Those activities either consume extra time or simply never get implemented, and both options are not very desirable. Employing a shared service allows engineering teams to centrally manage these challenges and build professional and robust solutions. Single teams can still pilot innovations in the context of a community of practice (CoP) and distribute them later to all service consumers without much additional effort.
Include Security Governance in the Transformation
Achieving benefits associated with shift left and eliminating bottlenecks requires a new mindset—a different way of thinking. For starters, we need to engage governance personnel early in any SAFe transformation—without them in the shared organizational mindset, they can slow adoption.
Instead of enforcing obsolete doctrine or creating unreachable requirements, the governance function becomes the trusted advisor working with the teams to understand required measures, help them learn required skills, and establish the required environment for success. Special reviews and checkpoints that hinder product development flow are eliminated; the responsibility for security moves to the teams.
Teams also require a mindset shift of ‘Embrace the Inspector’ [4] that views governance as a resource to help improve the solution rather than a burden. As soon as teams understand that they have full responsibility for the security in their solution, they will proactively seek assistance and make decisions in the best interest of the business. This includes complete transparency for status and progress, including exposing agreed KPIs.
In this model, security governance becomes responsible for creating an environment for teams to be successful and advancing the maturity of the organization by:
- Developing a security classification process and helping to apply it
- Creating and providing required training
- Deploying ambassadors to work temporarily with the teams and transfer knowledge
- Providing help with threat modeling
- Facilitating the development and evolution of coding standards
- Facilitating a security Community of Practice
- Working with the teams and the software factory to provide standardized security services
- Working with the security response team to gain further knowledge about existing vulnerabilities and share relevant information with the teams
- Selecting and managing appropriate vendors for penetration testing
- Providing security self-assessments
| STE/RTE/ DevMgr |
Solution Architect |
System Architect |
Agile Team Security Champion(s) |
Developers | Testers | |
| Security Development Lifecycle | high | high | high | high | high | high |
| Threat Modelling | medium | high | high | high | medium | low |
| Development language-specific secure coding | low | x | medium | low | high | low |
| Identifying insecure code patterns | low | x | high | medium | high | medium |
| Security Testing for QA | low | x | medium | medium | medium | high |
| Data Privacy | medium | x | medium | medium | medium | medium |
Table 5: Example of a basic Security Training Matrix
Roles and responsibilities
Security is usually hosted in an InfoSec or cybersecurity department with teams that are often surprised by these new Agile initiatives and naturally resist new demands. This is understandable because, from a local optimization point of view, the benefits are not obvious. SAFe helps here to explain the global optimization approach and organizing around value. These kinds of changes are substantial organizational changes and senior management must understand and drive the change by explaining the benefits of the new mindset and approach to the organization and by incentivizing desired behavior.
To improve collaboration between the governance function and the teams, define ‘security champions’ who are part of the teams or trains that are responsible for implementing security. They might not be intended as full-time roles but can be offered to appropriate candidates, such as a Solution Architect at the large Solution level, a System Architect at the ART level, and a team member on the Agile Team.
Summary
Enterprise software development is a complex endeavor that requires applying multiple different models, principles, and practices. Figure 10 provides an overview of those discussed in this article and highlights the interdependencies between them. Figure 10 also shows the application of SAFe Principle #2 – Apply systems thinking and the value of understanding the bigger picture instead of focusing on local optimization.
Let’s take a look at the diagram:
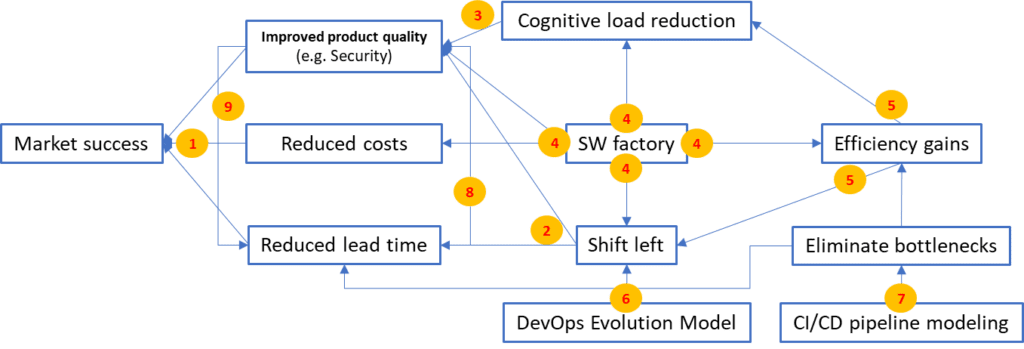
- Reduced lead time, improved product quality, and reduced costs lead to higher market success
- Shift left reduces lead time and increases product quality
- Cognitive load reductions lead to better product quality (teams can acquire deeper knowledge and skills)
- Software factory reduces cognitive load, improves product quality, reduces costs, creates efficiency gains, and enables shift left
- Efficiency gains reduce cognitive load and enable shift left (reduced transaction costs)
- DevOps Evolution Model is a systematic model to drive shift left
- CI/CD pipeline modeling identifies bottlenecks. The reduction of bottlenecks leads to reduced lead times, efficiency gains, and improved product quality
- Reduced lead time leads to improved product quality (shorter feedback cycles)
- Improved product quality leads to reduced lead time (less rework)
Armed with SAFe guidance, DevSecOps practices, and discussed models, organizations can effectively accelerate flow and increase value to the business.